Concepts¶
Architecture Overview¶
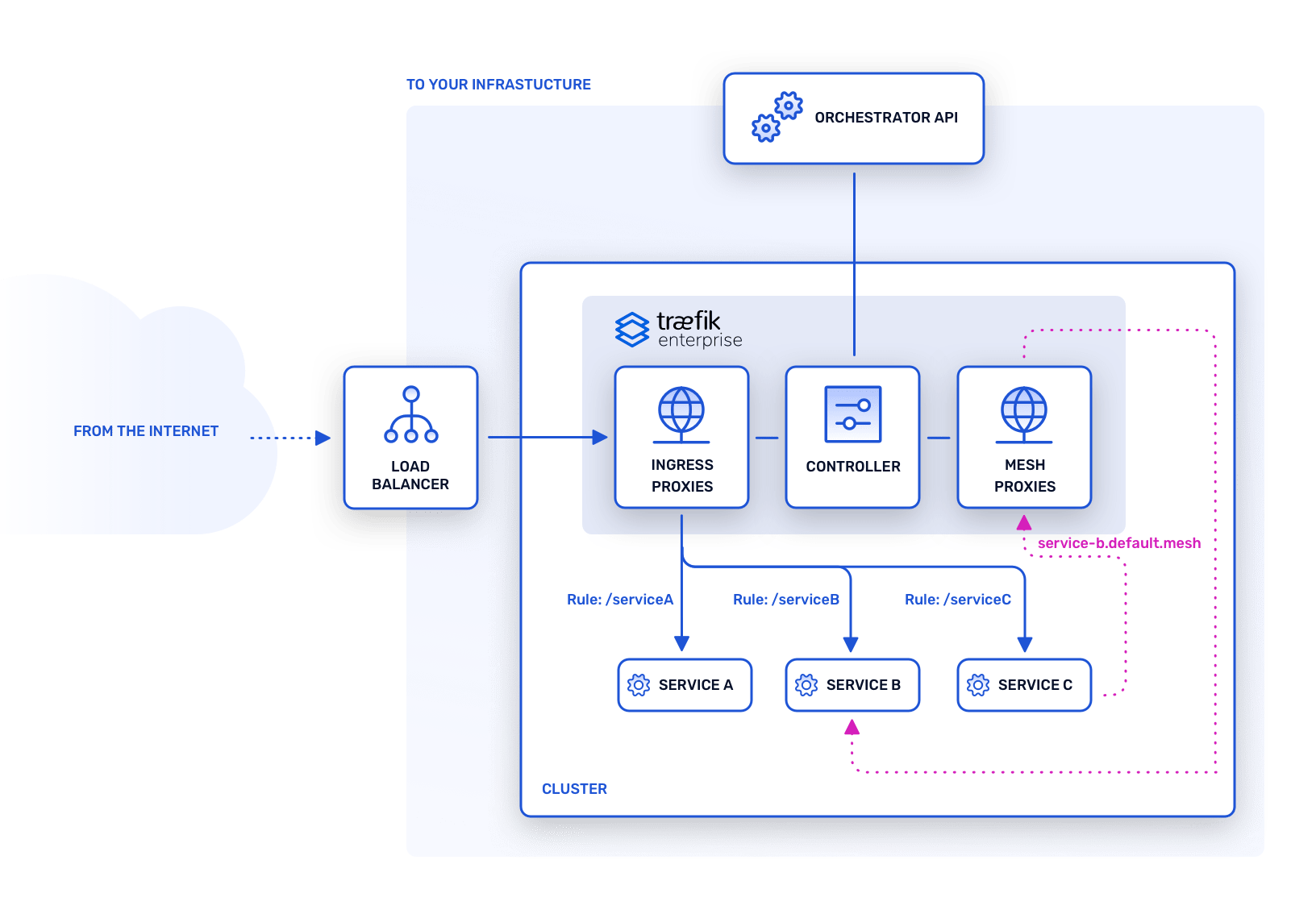
Traefik Enterprise's architecture consists of nodes spread into two different planes: the control plane and the data plane. The notions of control plane and data plane are well-known patterns and are not specific to Traefik Enterprise.
New. In addition, Traefik Enterprise 2.2 introduces optional service mesh capabilities when running on a Kubernetes cluster.
As mentioned in the introduction:
- The data plane hosts horizontally scalable nodes that forward ingress traffic to your services.
- The control plane hosts distributed nodes that watch your platform and its services to configure the data plane.
- The service mesh facilitates and controls inter-process communication between services running on your cluster.
This distributed architecture is the cornerstone of Traefik Enterprise’s strengths: natively highly available, scalable, and secure.
Of course, every (non-deprecated) feature that is available for Traefik Proxy is also available for Traefik Enterprise.
Cluster and Nodes¶
Traefik Enterprise consists of a cluster of nodes communicating with one another. Each node is independent and belongs to either the control plane, the data plane, or the service mesh.
Nodes in the Data Plane¶
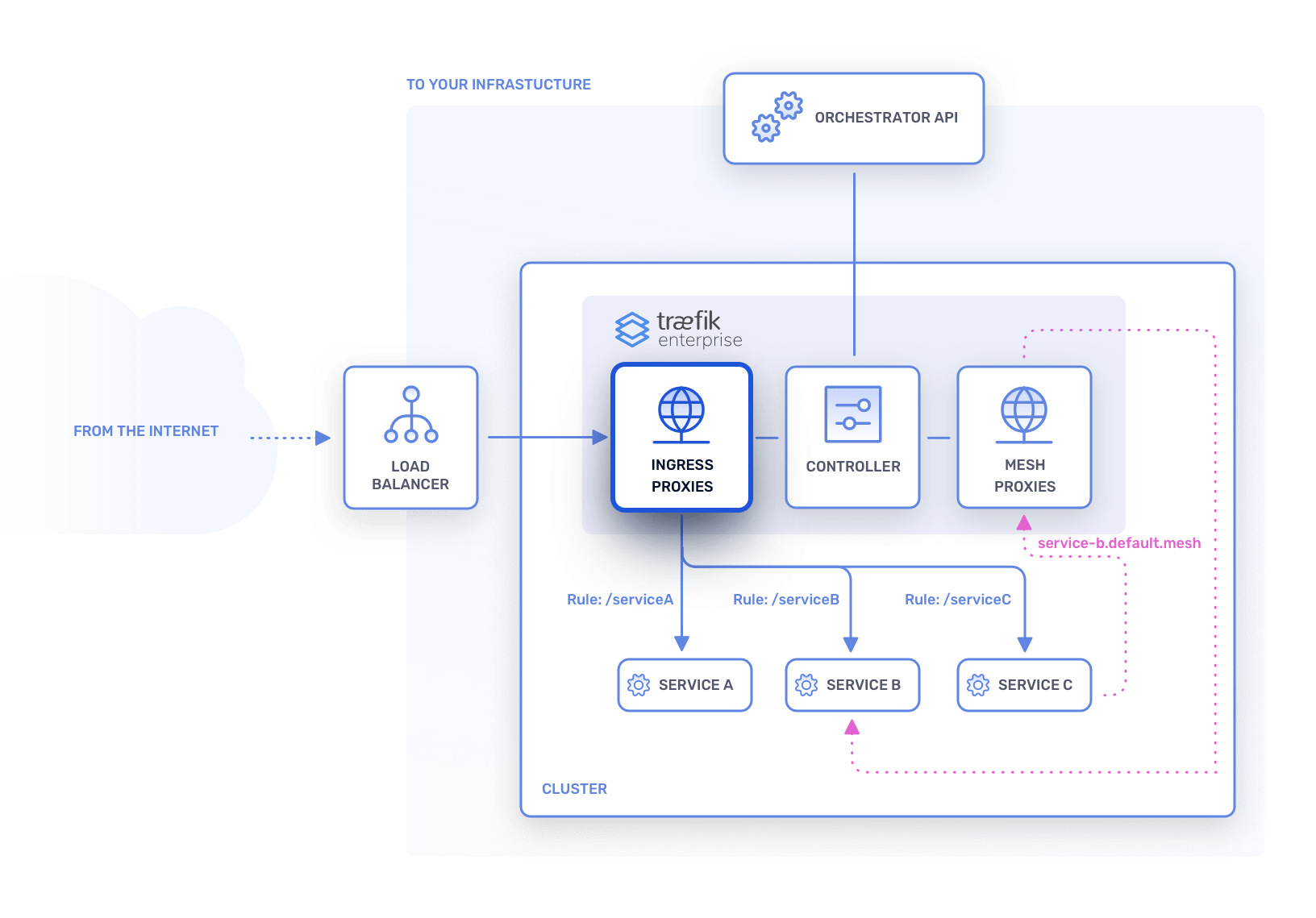
These nodes are the workers that route the incoming requests. You may view these nodes as regular Traefik Proxy instances that are automatically configured by other nodes from the control plane.
These nodes know nothing about your other infrastructure components and won't need to communicate with them.
Nodes in the Control Plane¶
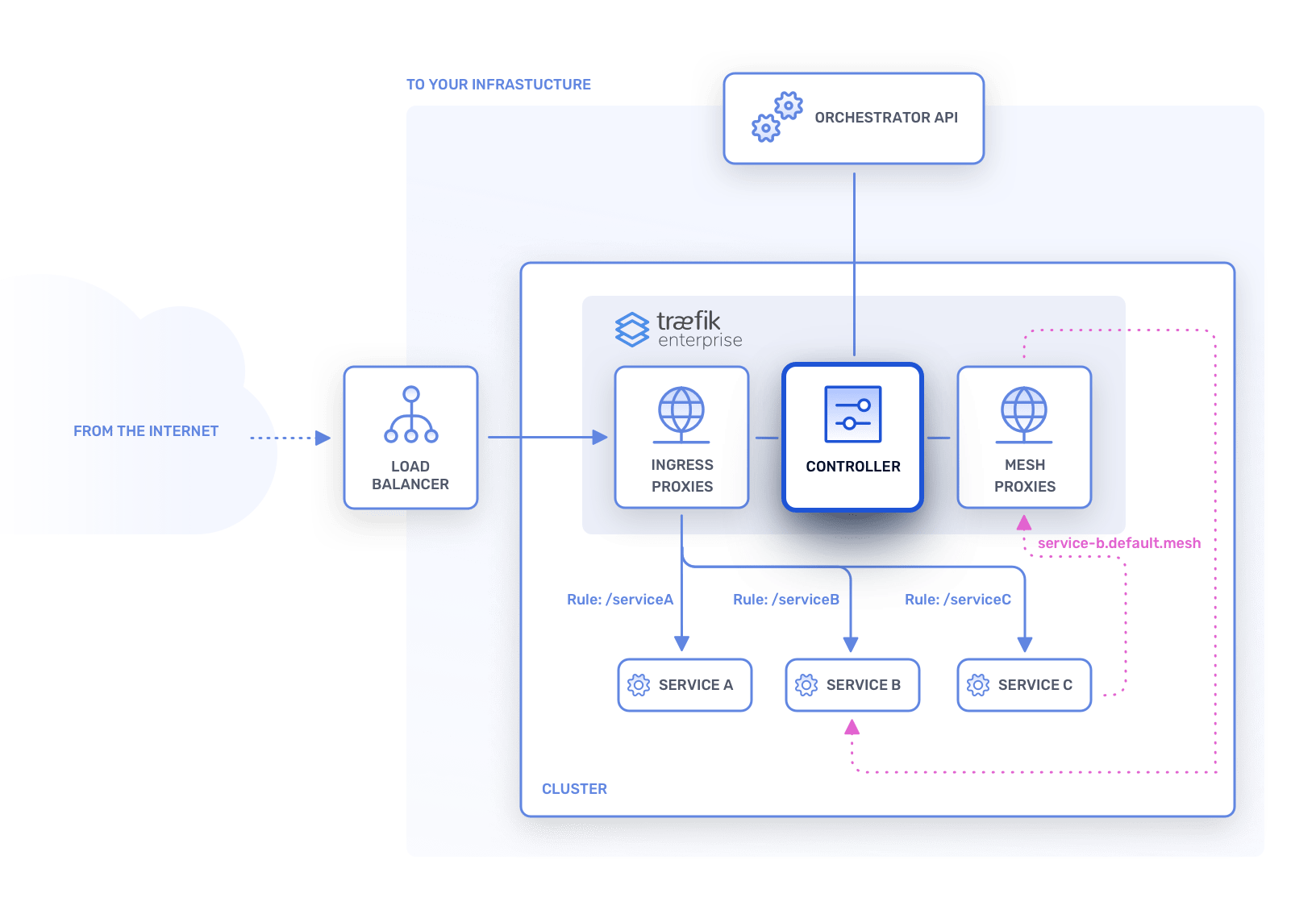
These nodes are responsible for querying your infrastructure components, creating the resulting configuration, and sending the routing instructions to the nodes in the data plane. These nodes will not handle incoming traffic.
Their main responsibilities are:
- Storing the data of the cluster, including events, certificates, and Traefik Proxy configuration.
- Sharing the data of the cluster as a distributed key-value store with all other nodes in the control plane.
- Propagating the latest configuration to the nodes in the data plane.
- Providing an API to configure the cluster and to query its state.
- Managing the dynamic configuration.
Service Mesh¶
New. When running on a Kubernetes cluster, in addition to managing incoming external traffic to services, Traefik Enterprise can also provide service mesh capabilities based on the Service Mesh Interface (SMI) specification.
The services mesh facilitates and manages inter-process communication between services. Available features include access control, rate limiting, traffic splitting, and support for the circuit breaker pattern.
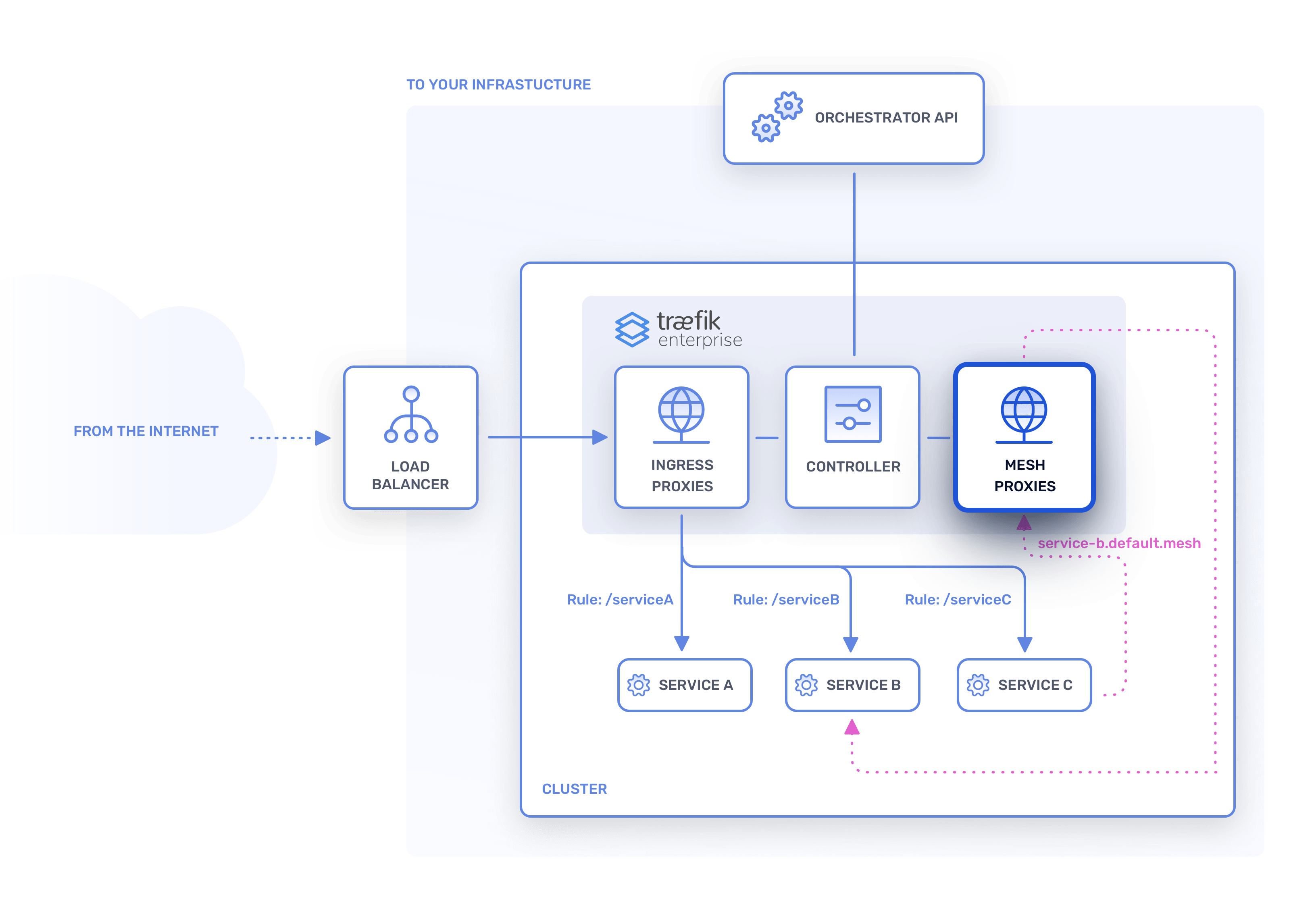
Traefik Enterprise's service mesh is based on the Kubernetes concept of a DaemonSet, which ensures that a service mesh proxy runs on each node of a cluster to handle communincation between services. The service mesh is designed to be non-invasive, meaning it requires no sidecar containers, does not modify your Kubernetes objects, is opt-in by default, and does not modify your traffic without your knowledge.
High Availability¶
Traefik Enterprise nodes work together to form a high-availability cluster, which Traefik Enterprise manages using the Raft algorithm. (For a visual explanation of Raft, see here.)
Nodes in the cluster can have three different roles:
- Agent: a node that accepts requests on behalf of the leader.
- Controller: an agent responsible for querying your infrastructure components. Controllers form a quorum to assume cluster HA.
- Leader: a controller responsible for updating/querying the state of the cluster.
When a leader node becomes unavailable, if the quorum is not broken, the other controllers elect a new leader among the healthy controllers.
When a controller node becomes unavailable, if the number of healthy controllers (including the leader) is not sufficient, the quorum is broken and the cluster is down.
When an agent node becomes unavailable, the cluster state doesn't change and it does not need to react.
If a new healthy node wants to join the cluster, it will participate as an agent or controller.
HA in the Data Plane¶
A node in the data plane is an agent. In Traefik Enterprise we call these nodes ingress proxies.
Each node in the data plane can handle the routing for every configured request that arrives in your cluster. If a node becomes unavailable, the other nodes will take over and accept more incoming requests.
The data plane only needs one healthy agent to be functional.
HA in the Control Plane¶
Nodes in the control plane are responsible for the routing configuration and applying changes to the state of the cluster. In Traefik Enterprise we call those nodes controllers. One of the controllers will be elected as the leader of the cluster.
A controller will send the configuration change requests to the leader who will then update the cluster state.
Common Questions¶
How Many Nodes Do You Need in the Control Plane?¶
The cluster is healthy as long as the nodes in the control plane can reach a quorum to elect a new leader in case of failure. The quorum is (N/2)+1 where N is the initial number of nodes in the control plane. If the number of healthy nodes goes below this number, the cluster must be recovered before it resumes normal operations.
What Happens if the Control Plane is Unhealthy?¶
The data plane will continue to route the requests based on the latest known configuration.
Scalability¶
Proxies and controllers can both be scaled horizontally by deploying more nodes.
Load balancing the incoming requests between Traefik Enterprise proxies is achieved by your infrastructure components (e.g., using Services in Kubernetes).
New. On Kubernetes clusters, Traefik Enterprise's service mesh DaemonSet ensures that a service mesh proxy runs as a pod on each node. A new service mesh proxy instance will automatically be created on each new node that is added to the cluster.
About Auto Scaling
Depending on your infrastructure components, you may benefit from auto-scaling tools that will help you automatically scale up/down your nodes as needed. For instance, for Kubernetes, here is a guide to set up a Horizontal Pod Autoscaler.
Security¶
Having two separate planes for handling different responsibilities improves the resilience of your cluster and also makes it more secure: nodes in the control plane are not exposed to the outside, making an attack against your infrastructure more difficult.
What's Next?
Now that you have a basic overview of Traefik Enterprise's concepts, to further familiarize yourself with the vocabulary, have a look at the glossary.